前端监控 - Web SDK
背景
大家是否也碰到过下面这几个问题? 是不是也感到束手无策?
- 页面在用户端早就大面积崩溃了,隔了几十分钟甚至几小时才一脸懵逼地收到来自用户的投诉?
- 在我这里是好的,在用户那里就崩溃了?为啥?
- 查个工单各部门来回踢皮球,却拿不出有力证据?
- 整天想要提升用户体验,却不知道从何处下手?
前端性能监控系统应运而生,他要着重解决:
- 异常感知
- 异常诊断
- 全链路追踪
- 用户关键行为监控
- 可视化分析
从大的功能模块角度,我们把它分为三个部分,上层应用、数据中心和数据收集,今天我们主要聊一下 Web SDK 数据收集部分的一些功能点
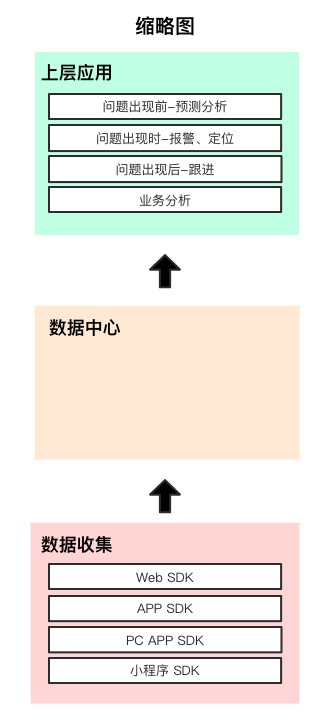
数据收集
Web SDK
Web SDK 的目标是做到“无侵入”,业务代码无需改造,页面引入 SDK 代码即可,指标自行收集。 主要收集 4 项指标:
- 异常数据
- 页面性能
- 接口监控请求
- 静态资源加载
Web SDK 模块
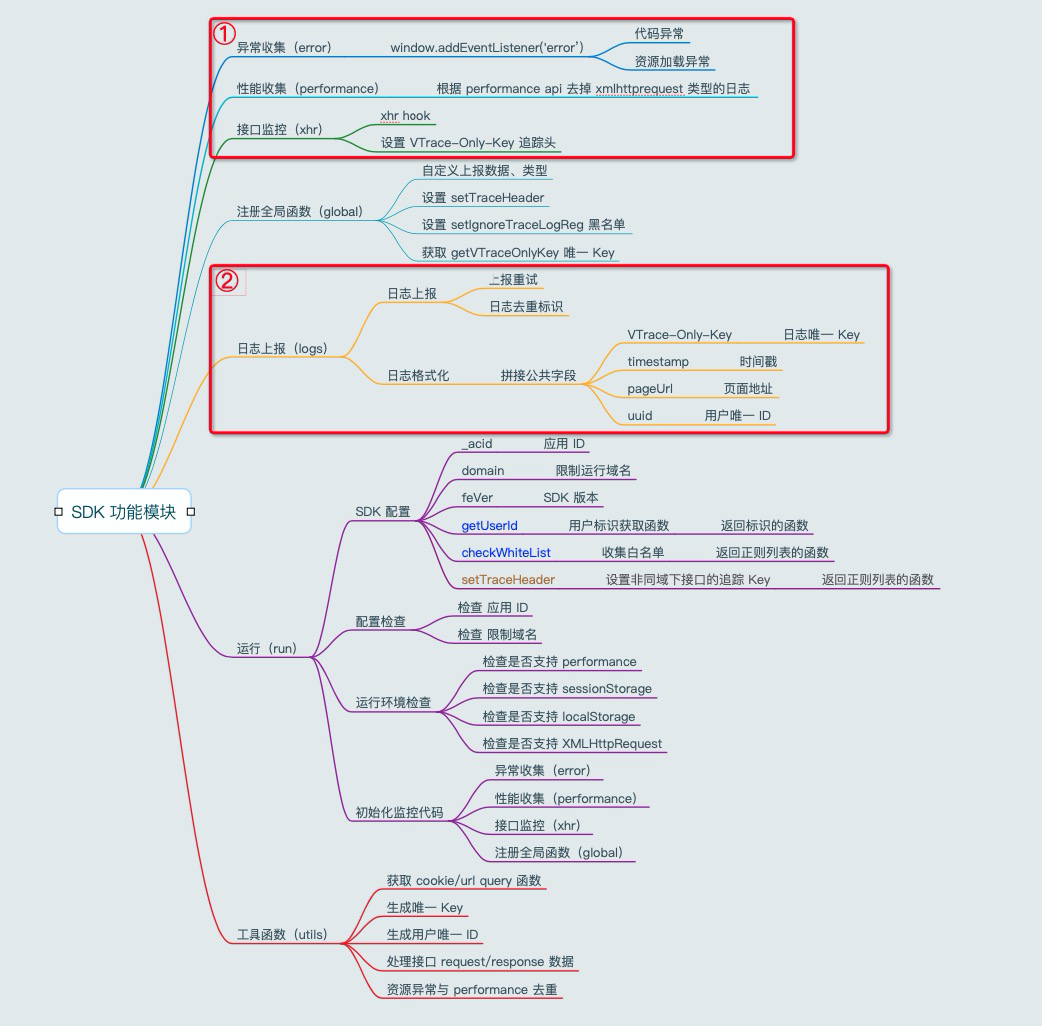
有两个主要的部分: ① 日志收集部分:负责监听事件收集日志,调用日志上报发送日志 ② 日志上报部分:组织日志分批上报,重试,缓存,配合去重等
异常收集
用于收集资源加载异常,和代码报错异常
监听代码:
// 监听 window error
window.addEventListener('error', function (event) {
let data = null;
if (event instanceof ErrorEvent) {
data = dealCodeErrorData(event);
} else {
data = dealResourceErrorData(event);
}
data = transLogData(data);
saveLogs(data);
}, true);
// 监听 Promise reject --- 未实现
window.addEventListener('unhandledrejection', function (event) {
const data = dealPromiseErrorData(event);
data = transLogData(data);
saveLogs(data);
}, true);
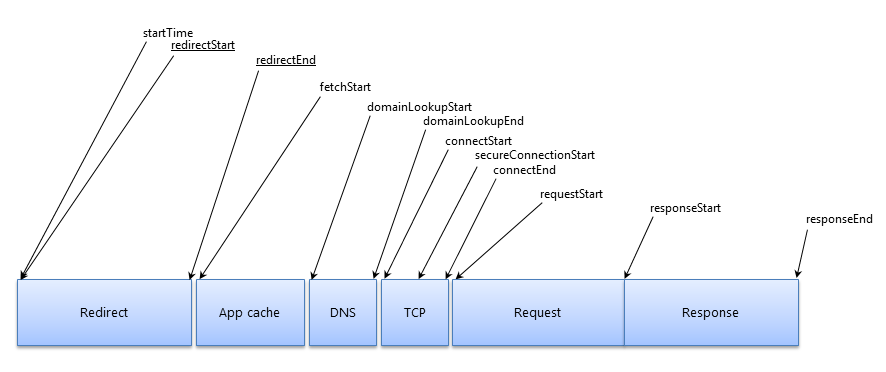
资源异常上报代码:
包含资源加载 timing 的收集,用于分析资源加载链路
const dealResourceErrorData = function (event) {
const { target } = event;
const { src, href } = target;
const url = src || href; // 不同的标签,链接放在不同的属性里
const data = {
type: constant.WEB_RESOURCE_ERROR,
resourceTagName: target.tagName,
resourceDomString: target.outerHTML,
resourceUrl: url,
};
let entries = pf.getEntriesByName(url);
// 由于 src 或 href 为空的时候,url 会取到域名+根路径,所以必须从标签上检测
if (target.outerHTML && (/(href|src)=""/.test(target.outerHTML) || !/(href|src)="/.test(target.outerHTML))) {
data.type = constant.WEB_TAG_EMPTY;
} else if (url && entries.length) { // 资源异常数据
const entry = entries[entries.length - 1];
data.resourceType = getFileType(url);
data.timing = transTiming(entry);
pushErrorEntry(entry);
}
return data;
};
资源异常上报代码: 配合 sourceMap 还原到源代码异常位置
const dealCodeErrorData = function (event) {
const stack = (event.error && event.error.stack) || '';
const data = {
type: constant.WEB_CODE_ERROR,
codeFilename: event.filename,
codeColno: event.colno,
codeLineno: event.lineno,
codeMessage: event.message,
codeStack: stack
};
return data;
};
静态资源收集
通过 performance api,监听每一个资源的加载,并记录 performance 监听代码:
const lunchPerformanceObserver = function (config) {
const po = new PerformanceObserver(function (entryList) {
const entries = entryList.getEntries();
// 放到执行队列后边,以解决 window error 触发滞后,无法去重的问题
setTimeout(() => {
saveLogs(getResourceSyncList(entries, config));
}, 0);
});
po.observe({entryTypes: ["resource"]});
}
资源加载上报:
const getResourceSyncList = function (entries, config) {
const resultList = [];
entries.forEach((entry, index, arr) => {
// 非 xhr 才走资源上报
if ((entry.initiatorType !== 'xmlhttprequest')) {
const { name, duration, initiatorType } = entry || {};
// 检查是否在白名单中
if (!isInWhiteList(config, (name || ''))) return;
// 检查是否在黑名单中
if (ignoreLog(constant.WEB_IGNORE_TRACE_LOGS_REG_LIST, (name || ''))) return;
// 检查是否已经是报错条目(去重)
if (checkErrorEntryExist(entry)) return;
// 处理资源类型
const data = { type: constant.WEB_PERFORMANCE_RESOURCE };
data.resourceType = getFileType(name);
data.resourceUrl = name || '';
// 时间大于最小收集基线时才收集全部 timing 信息
if (duration >= config.minCollection) {
data.timing = transTiming(entry);
} else {
data.timing = { name, duration, initiatorType };
}
resultList.push(transLogData(data));
}
});
return resultList;
};
页面性能数据收集
通过 Navigation Timing Api 获取页面加载性能指标
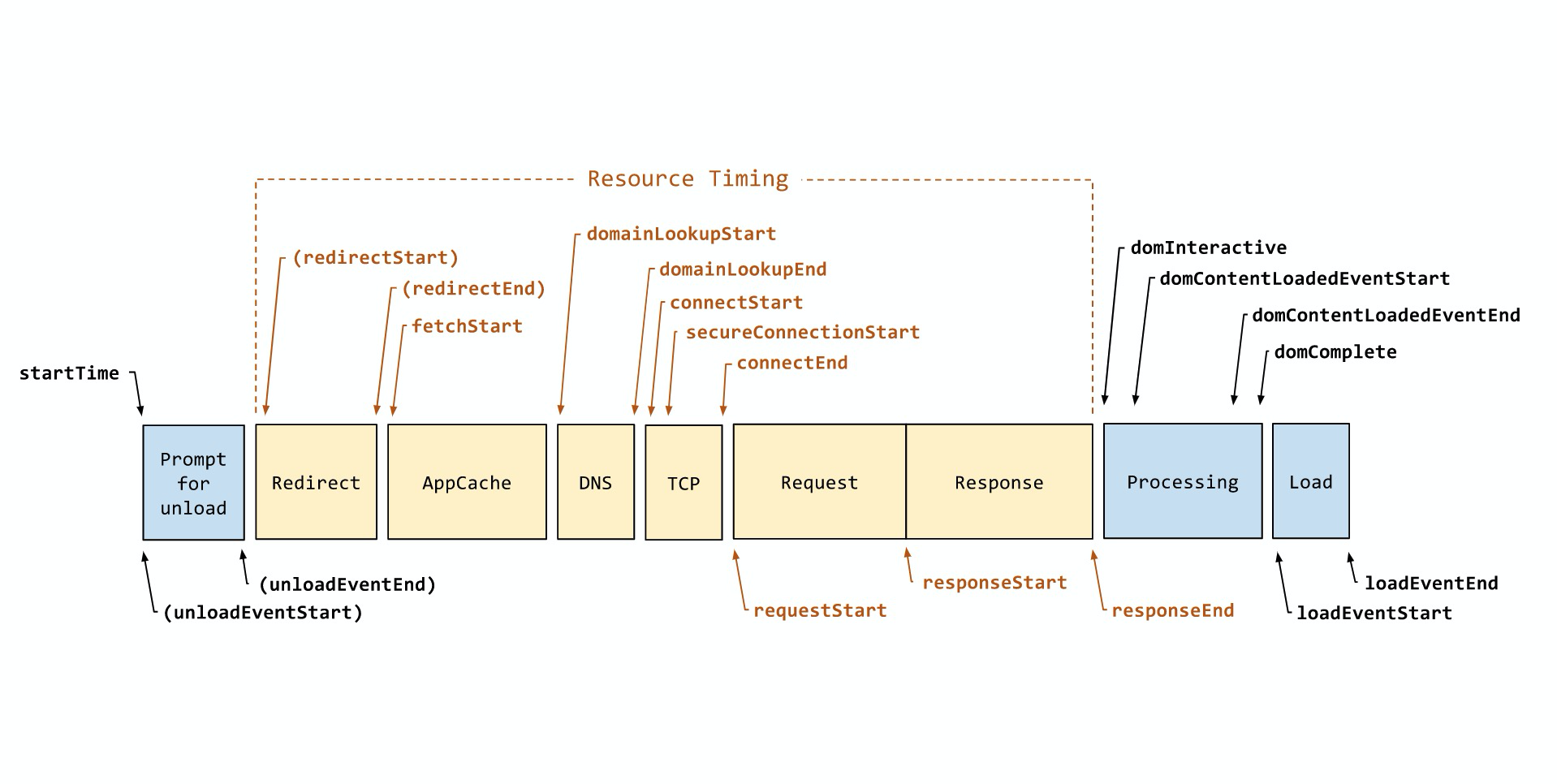
计算公式:
| 表头 | 表头 | 计算公式 |
|---|---|---|
| ttfb | 首字节时间 | responseStart - requestStart |
| domReady | Dom Ready时间 | domContentLoadedEventEnd - fetchStart |
| pageLoad | 页面完全加载时间 | loadEventStart - fetchStart |
| dns | DNS 查询时间 | domainLookupEnd - domainLookupStart |
| tcp | TCP 连接时间 | connectEnd - connectStart |
| ssl | SSL 连接时间 | secureConnectionStart > 0 ? connectEnd - secureConnectionStart) : 0 |
| contentDownload | 内容传输时间 | responseEnd - responseStart |
| domParse | DOM 解析时间 | domInteractive - responseEnd |
| resourceDownload | 资源加载耗时 | loadEventStart - domContentLoadedEventEnd |
| waiting | 请求响应 | responseStart - requestStart |
| fpt | 白屏时间,老 | responseEnd - fetchStart |
| tti | 首次可交互 | domInteractive - fetchStart |
| firstByte | 首包时间 | responseStart - domainLookupStart |
| domComplete | DOM 完成时间 | domComplete - domLoading |
| fp | 白屏时间,新 | performance.getEntriesByType(‘paint’)[0] |
| fcp | 首次有效内容绘制 | performance.getEntriesByType(‘paint’)[1] |
| lcp | 首屏大内容绘制时间 | PerformanceObserver(‘largest-contentful-paint’)” |
| 快开比 | 页面完全加载时长 ≤ 某时长(如2s)的 采样PV / 总采样PV * 100% | |
| 慢开比 | 页面完全加载时长 ≥ 某时长(如5s)的 采样PV / 总采样PV * 100% |
接口请求数据收集
通过 hook XMLHttpRequest 的属性和方法来监控接口请求,以及在请求 header 中添加用于全链路追踪的唯一 Key
hook 方案: https://github.com/wendux/Ajax-hook
接口监控上报:
hook(['open', 'onerror', 'send', 'onreadystatechange', 'setRequestHeader', 'abort', 'readyState', 'status', 'responseURL'], {
open([method, url]) {
// 可能存在链接不写协议的情况,这里拿到的 url 里没有补上,需要补上才能在 timing 中找到。
this.requestUrl = /^\/\//.test(url) ? window.location.protocol + url : url;
this.VTraceOnlyKey = getVTraceOnlyKey(config);
this.isTraceHeader = isSetTraceHeader(url) || shouldSetHeader(url);
this.vMethod = method;
},
onerror(err) {
console.log(err.stack);
},
send(data) {
if (this.isTraceHeader) {
this.setRequestHeader('VTrace-Only-Key', this.VTraceOnlyKey);
}
this.requestData = data && data[0];
},
onreadystatechange(xhr) {
const url = xhr.responseURL || this.requestUrl;
if (xhr.readyState === 4 && isInWhiteList(config, url) && !ignoreLog(ignoreTraceLogsRegList, url)) {
setTimeout(() => {
const entries = _performance.getEntriesByName(url);
const entry = entries[entries.length - 1] || {};
saveLogs(transInterfaceData(this, xhr, entry, config));
}, 0);
}
}
});
日志上报
日志上报主要有三个逻辑
- 缓存
- 发送
- 重试
缓存
需要维护一个全局的发送队列,缓存各监听程序发送来的日志,并设置最大缓存条数,如 300 条,到达最大值后,就开始丢点,防止撑爆内存
在添加到队列之前,可以组装日志的通用字段
发送
从队列中截取一定个数的日志,如 15 条,打包发送,提升上报效率的同时,也能控制请求个数。
发送失败的话再放回到队列中,触发重试机制
重试
防止日志丢失,需要有重试机制,我们设定为连续重试 3 次,如果还不成功,延迟 5 分钟加一个随机秒后继续重试
随机秒这个设计由来,如果发生大规模的网络故障,如果都是固定的 5 分钟重试,会在恢复的一瞬间,有及大量的上报同时触发,可能导致收点服务阻塞,可能造成丢点
SDK 使用
目前推荐,并且只支持同步加载的方式,放在页面头部最前面,异步的方式可能有 js 异常监控不到
日志加速上行
日志的上报加速也是一个复杂的课题,这里只简单介绍我们做了的
日志内容瘦身
这里很好理解,主要策略就是减少上报日志的体积,主要分两个方面:
- 减少冗余字段:由于历史原因,会上报一些多余的字段,需要在上层应用建设的过程中逐步筛选
- 减少字段有效长度:刚开始建设的时候,由于不知道字段会用多少,所以有些字段上报的内容比较长,适当进行优化截取
- 错误日志合并:对一些不影响页面浏览的异常,比如一些由开发人员编码不当造成的图片标签 src 为空的异常,在收集时对其进行合并,只上报数量
- 正常日志瘦身:在所有收集上来的日志中,95% 以上都是正常日志,虽然必要,但不用具体分析每个请求的内容,所以删减其上报的字段,能标识一个正常请求即可
去重标识
收点接口必须要做日志去重,逻辑是这样的,发送一个日志上报请求时,服务端已经接收到了,客户端有可能收不到服务端的响应,导致启动重试机制,会产生重复日志。
最初我们是全量去重的,每上来一条日志就执行去重逻辑,但是随着日志量越来越大,去重逻辑成为收点的瓶颈。
所以我们在 SDK 上报时设置了一个重试标记,服务端在收到有重试标记的上报请求时,才执行去重逻辑,极大提升了收点效率。